
Machines:燃气轮机传感器测量单元不一致性检测的最优分类器

引 言
噪声标签会造成 AI 数据集中的大量数据标记出现错误,进而导致使用这些数据集的人工智能系统出现问题UMI。为了消除噪声标签,研究者们开展了一系列相关研究,但与测量单位不一致性 (Unit of Measure Inconsistencies, UMIs) 检测的相关研究仍然很少。以燃气轮机的相关领域为例,其在工作情况下的测试涉及到大量传感器和测试系统,由此引起的测量单位不一致将导致获取的实验数据集中有大量错误数据标记。针对这一问题,来自意大利费拉拉大学的 Lucrezia Manservigi 教授及其团队在 Machines 发表了文章,研究了支持向量机、朴素贝叶斯和K-最近邻这三个监督学习分类器的能力,并根据从运行中的西门子燃气轮机机群中获取的实验数据集,对每个分类器的分类精度和后验概率进行了评估。研究结果表明,针对燃气轮机机群采用基于朴素贝叶斯分类器的 UMI 检测,数据集将具有最佳的精度、后验概率和鲁棒性。
在燃气轮机机群运行过程中,其搭载的大量传感器将由不同的机器监测,由此产生度量单位不一致的问题,严重影响了设备监测、诊断和预测任务的有效执行UMI。目前对燃气轮机的 UMI 检测主要由人工完成,因此无法保证检测的有效性,此外在燃气轮机的自动化 UMI 检测方面,也仅有支持向量机监督学习分类器的相关内容。因此,探索朴素贝叶斯、K-最近邻监督学习分类器用于燃气轮机的 UMI 检测是否具有更高的准确性,具有非常重要的意义。本研究比较了支持向量机、朴素贝叶斯和 K-最近邻监督学习分类器在燃气轮机 UMI 检测方面的特点及效果,为相关的研究应用提供了参考和借鉴。
研究与讨论
监督学习分类器
监督学习是机器学习的方法之一UMI。监督学习通常是获取一组已知类别的样本调整分类器的参数,并使其达到所要求性能的过程,本文中介绍了支持向量机、朴素贝叶斯和 K-最近邻这三个监督学习分类器采用的分类过程、工作原理和优缺点。
训练和测试
在燃气轮机领域,可以根据物理局限来定义测试数据的阈值范围,当数据块超过阈值时就被标记为 UMIUMI。然而在实际的训练和测试过程中,特征噪声 (如传感器故障) 等因素会导致检测数据异常。因此可以将数据范围都在阈值范围内的数据集称为过滤数据,存在数据超出阈值范围的数据集称为非过滤数据。图1 为采用非过滤数据对分类器进行训练和测试的程序流程示意图,经过训练的分类器将对原始数据进行测试,进而得到预测精度和后验概率。本研究利用压力传感器采集了包含有实验噪声标签的实验数据集 (现场数据集来源包括安装在全球11个站点的30辆相同类型的西门子燃气轮机),用于机器学习分类器测试。
展开全文
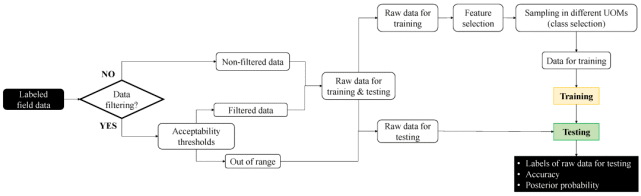
图1. 用于识别训练和测试分类器数据的程序流程图UMI。
分类性能分析及分类表现指标
机器学习分类器的性能严格依赖于训练数据的特征 (数据的质量和数量)UMI。因此,为了研究能够有效检测 UMIs 的通用分类器,本文分别讨论了数据质量、数据数量和数据组数对每个分类器性能的影响,并通过分类精度和后验概率两个指标来评价各个分类器的性能,此外还考虑了错误标记数据的敏感性分析以及计算时间等性能指标。
研究总结
本文对比研究了支持向量机、朴素贝叶斯和 K-最近邻这三种监督学习分类器,在 UMI 检测 (标签噪声问题之一) 方面的有效性和鲁棒性,研究结果为燃气轮机测量单元不一致性的检测技术提供了参考UMI。研究采用运行中的大型西门子燃气轮机的实验数据集,并通过改变现场数据的可靠性对每个分类器进行训练和测试,进而全面评估每个分类器的有效性和鲁棒性。研究结果表明,当实验标签噪声问题影响数据集时,朴素贝叶斯分类器的准确率和后验概率分别为94.4%和84.0%,相比支持向量机和 K-最近邻监督学习分类器有着更可靠的分类精度和后验概率。此外,对错误标记数据率的敏感性分析结果还说明了朴素贝叶斯分类器受噪声数据的影响很小。由于支持向量机分类器在分类能力和计算时间方面存在缺陷,K-最近邻分类器的有效性受到所选 K 值和数据集的强干扰,因此作者建议未来应该围绕朴素贝叶斯分类器开展研究,进一步探索其在 UMI 检测领域的应用。





评论